Here we show some of the most common ElasticSearch curl commands. ElasticSearch is sometimes complicated. So here we make it simple.
(This article is part of our ElasticSearch Guide. Use the right-hand menu to navigate.)
Background information
What is “curl”?
The acronym cURL, now frequently spelled curl, stands for client URL. It is a command line tool that lets you transfer data to or from web servers, APIs, and other networked devices. Developers find that it is an essential tool for use in web development projects, for automation and scripting tasks, and for managing IT systems.
Using ElasticSearch curl commands
For large-scale data indexing and querying, curl ElasticSearch is a powerful distributed search and analytics engine. You can directly access the ElasticSearch RESTful API using curl to create indexes, search through documents, update data, and for managing cluster computing. Here is a curl ElasticSearch commands cheat sheet:

ElasticSearch indices commands using curl
An ElasticSearch index is a set of signs that identify and refer to a set of documents that are a collection of fields, all holding data. What makes it elastic, as opposed to a fixed schema, is that you don’t have to map things out in advance. It lets you explore your data without requiring you to define your fields. It automatically detects and maps your fields dynamically.
Create index in ElasticSearch
The ElasticSearch command below creates an index named index_name with default settings.
curl -X PUT 'http://localhost:9200/index_name'
Delete an ElasticSearch index
To delete an ElasticSearch index (in this case, named samples), use the following curl command:
curl -X DELETE 'http://localhost:9200/samples'
List all indices
To list all indices in ElasticSearch, use:
curl -X GET 'http://localhost:9200/_cat/indices?v'
List all docs in index
Below is an curl ElasticSearch query to return all documents from an index:
curl -X GET 'http://localhost:9200/sample/_search'
List index mapping
All ElasticSearch fields are indexes. So this ElasticSearch curl command lists all fields and their types in an index.
curl -X GET http://localhost:9200/samples
Back up an ElasticSearch index
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"source": {
"index": "samples"
},
"dest": {
"index": "samples_backup"
}
}'
How to query ElasticSearch using curl
When you query ElasticSearch using curl, you can use URL parameters or send an HTTP GET request with a JSON body that contains the query. Here are examples of both approaches:
ElasticSearch curl query using URL parameters
Below is a simple curl to get an ElasticSearch curl command example, useful for basic queries and operations. Here we use Lucene query format to write q=school:Harvard.
curl -X GET http://localhost:9200/samples/_search?q=school:Harvard
Query with JSON aka ElasticSearch Query DSL
You can query using parameters on the URL. But you can also use JSON to query ElasticSearch using curl, as shown in the next example. JSON would be easier to read and debug when you have a complex query than one giant string of URL parameters.
curl -XGET --header 'Content-Type: application/json' http://localhost:9200/samples/_search -d '{
"query" : {
"match" : { "school": "Harvard" }
}
}'
ElasticSearch query returning only certain fields
To return only certain fields when querying ElasticSearch using curl, put them into the _source array:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"_source": ["suricata.eve.timestamp","source.geo.region_name","event.created"],
"query": {
"match" : { "source.geo.country_iso_code": "GR" }
}
}
ElasticSearch query by date
When the field is of the type “date”, you can use date math, like this:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"query": {
"range" : {
"event.created": {
"gte" : "now-7d/d"
}
}
}
}
Curl put ElasticSearch commands
Add data
The curl command below adds data to an ElasticSearch document:
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/1 -d '{
"school" : "Harvard"
}'
Update doc
Here is how to add fields to an existing ElasticSearch document. First, we create a new doc, then we update it.
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2 -d '
{
"school": "Clemson"
}'
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2/_update -d '{
"doc" : {
"students": 50000}
}'
Other useful ElasticSearch curl command examples
Bulk load data in JSON format
Here’s how to bulk load data in JSON format to an ElasticSearch cluster:
export pwd="elastic:" curl --user $pwd -H 'Content-Type: application/x-ndjson' -XPOST 'https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/0/_bulk?pretty' --data-binary @<file>
Show ElasticSearch cluster health
The curl xget ElasticSearch command below uses JSON format to check ElasticSearch cluster health:
curl --user $pwd -H 'Content-Type: application/json' -XGET https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/_cluster/health?pretty
Aggregation and bucket aggregation
For an nginx web server, this ElasticSearch aggregation command produces web hit counts by user city:
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"cityName": {
"terms": {
"field": "geoip.city_name.keyword",
"size": 50
}
}
}
}
'
This expands that to a product response code count by city in an nginx web server log:
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"city": {
"terms": {
"field": "geoip.city_name.keyword"
},
"aggs": {
"responses": {
"terms": {
"field": "response"
}
}
}
},
"responses": {
"terms": {
"field": "response"
}
}
}
}'
Using ElasticSearch with basic authentication
If you have turned on security with ElasticSearch, then you need to supply the user and password as shown below to every curl command:
curl -X GET 'http://localhost:9200/_cat/indices?v' -u elastic:(password)
Pretty print ElasticSearch
Add ?pretty=true to any search to pretty print the JSON, like this:
curl -X GET 'http://localhost:9200/(index)/_search'?pretty=true]]>
MongoDB and Docker containers
Since MongoDB is among the most popular NoSQL databases today, you may find it necessary to run MongoDB as a Docker container. In this article, you’ll learn:
- The Benefits of using MongoDB in a Docker container
- How to install Docker
- How to install Docker Compose
- How to configure MongoDB as a Docker container
- How to establish external connections to MongoDB containers
- How to set up advanced Docker containers for MongoDB
At the end of this tutorial, we will look at advanced configurations that give you a glimpse of the extensibility of a containerized project. We will create a self-containing project with a MongoDB instance and Mongo Express web interface on a dedicated network, and Docker volume to maximize the portability of the project.
Let’s get started.
(This article is part of our MongoDB Guide. Use the right-hand menu to navigate.)
Benefits of using MongoDB in a Docker container
Docker is a tool to easily use containers to create, deploy, and run applications. A container is a standard unit of software that puts applications and all its dependencies in a single package. The value of such containers is that the software can run on any server platform, regardless of its hardware or configuration.
You can use Docker to run MongoDB instances. When you set up MongoDB Docker container instances, you can create a portable and extensible NoSQL database. This containerized MongoDB instance behaves exactly like a non-containerized MongoDB instance, without the worry of the server configuration.
Installing Docker
We will start this tutorial by setting up a simple Docker installation to run containers on a Ubuntu-based server. We can get the Docker installation packages from the official Docker repository. Here are the installation steps:
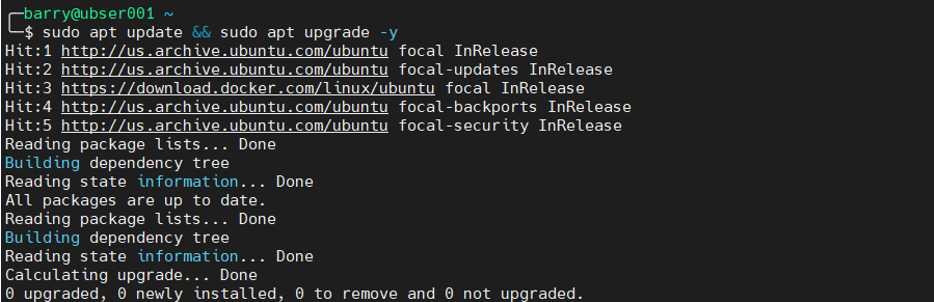
1. Update existing packages.
sudo apt update && sudo apt upgrade -y
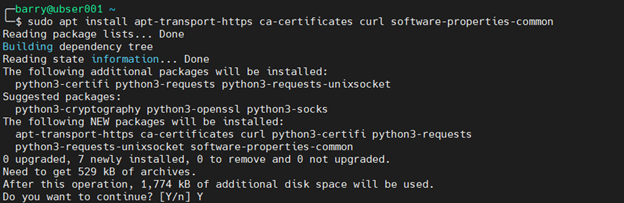
2. Install prerequisite packages.
sudo apt install apt-transport-https ca-certificates curl software-properties-common
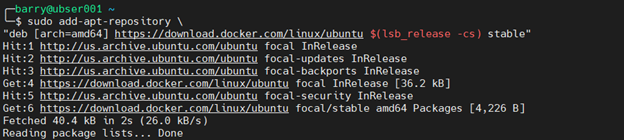
3. Add the GPG key from the official Docker repository.
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -

4. Add the official Docker repository to APT sources.
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
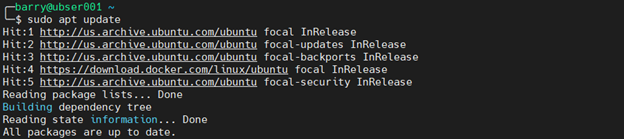
5. Update the Ubuntu package list.
sudo apt update
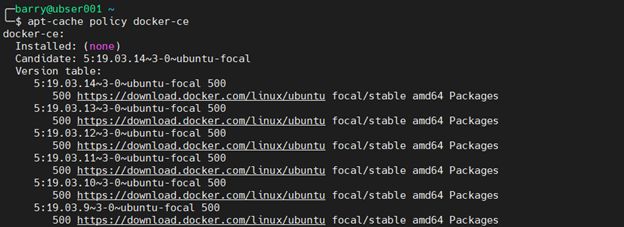
6. Verify the Docker repository.
apt-cache policy docker-ce
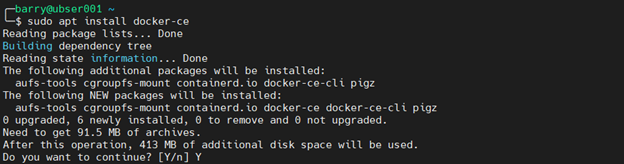
7. Install the Docker community edition.
sudo apt install docker-ce
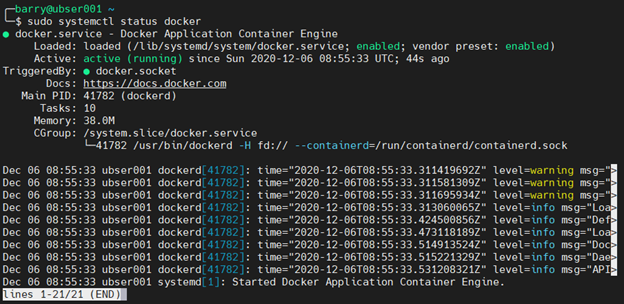
8. Check the status of the installation with the following command. If the service status returns active (running), Docker is successfully installed and active on the system.
sudo systemctl status docker
Installing Docker Compose
We can use the command line interface (CLI) to create and manage Docker containers. Using CLI can be tedious when dealing with multiple containers and configurations.
Instead, you can use Docker Compose to take multiple containers and integrate them into a single application. It uses the YAML format to create the Compose files that can be easily executed using docker-compose up or down commands that will create or remove all the containers and configurations within a Compose file, respectively.
Let’s install Docker Compose on the Ubuntu server.
1. Install the current stable release of Docker Compose.
sudo curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose

2. Apply executable permissions for the downloaded binary.
>sudo chmod +x /usr/local/bin/docker-compose
![]()
3. Verify the Docker Compose installation.
docker-compose --version

Setting up MongoDB using a Docker Compose container
This section explains how to set up a MongoDB container using a Docker Compose file.
Before we create the Compose file, let’s search for the official MongoDB container image using the search command.
sudo docker search mongodb

The search results show us that an official MongoDB container image called “mongo” exists in the Docker container registry.
By default, the MongoDB container stores the databases within the /data/db directory within the container.
Create a Docker Compose directory to hold MongoDB
Next, we need to create a directory called “mongodb” to hold the Docker Compose file. We will create another directory called “database” inside the “mongodb” directory to map to the database location of the container and enable local access to the database. We use the -pv operator to create those parent folders.
>mkdir -pv mongodb/database

The following docker-compose.yml file will be created within the “mongodb” directory to construct the MongoDB container.
docker-compose.yml
version: "3.8" services: mongodb: image : mongo container_name: mongodb environment: - PUID=1000 - PGID=1000 volumes: - /home/barry/mongodb/database:/data/db ports: - 27017:27017 restart: unless-stopped
We used version 3.8 to create the above Compose file. The Compose file version directly correlates to:
- Which options are available within the Compose file.
- The minimum supported Docker Engine version.
In this case, It’s Docker engine 19.03.0 or newer.
MongoDB service within the Docker container
In the Compose file, we have created a service called “mongodb” using the Docker image “mongo.” We have named the container “mongodb” and mapped the database folder within the container to the local database folder (/home/barry/mongodb/database.) These kinds of mappings are known as bind-mount volumes.
The environment variables are used to define the “user” and “group” of the container. Finally, we mapped the local port 27017 to internal port 27017. Then the restart policy is set to restart unless stopped by the user.
Here’s the file structure of the project:
tree mongodb

Starting the MongoDB Docker container
Go to the “mongodb” folder and run the docker-compose up command to start the MongoDB container. The -d operator runs the detached container as a background process.
sudo docker-compose up -d
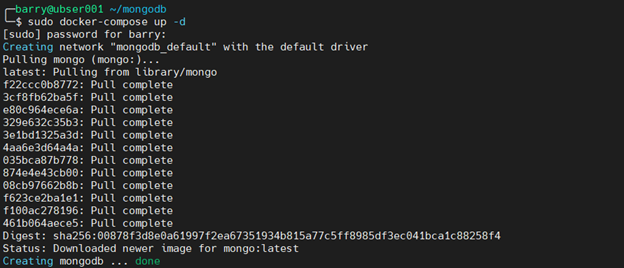
The up command will pull the “mongo” image from the Docker registry and create the container using the given parameters in the docker-compose.yml file.
Let’s verify if the container is running and the local folder is populated by using the following commands. The -a operator will display all the containers within the system regardless of their status.
sudo docker ps -a

sudo tree mongodb
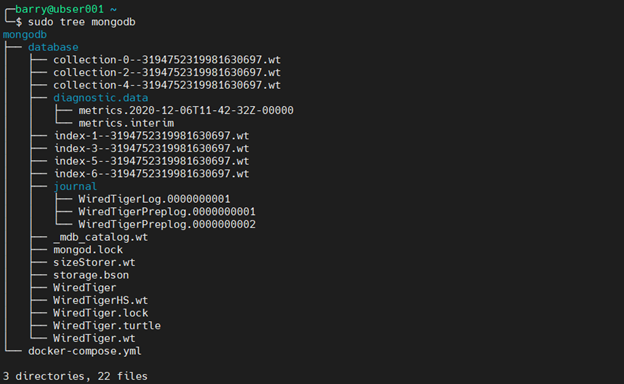
Interacting with MongoDB in a Docker container
Using the Docker exec command, we can access the terminal of the MongoDB container. Since the container runs in a detached mode, we will use the Docker interactive terminal to establish the connection.
sudo docker exec -it mongodb bash
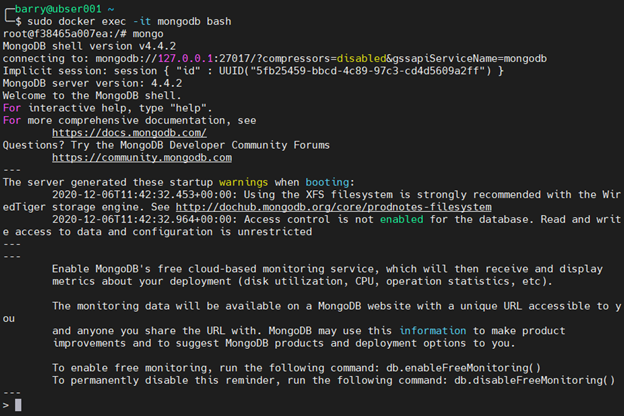
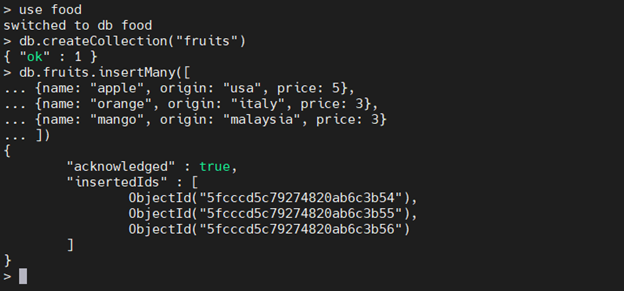
In the container’s bash terminal, we call the mongo command to access MongoDB. For this MongoDB Docker Compose example, we will create a database called “food” and a collection called “fruits,” along with three documents.
1. Switch the database.
use food
2. Create the collection.
db.createCollection("fruits")
3. Insert documents
db.fruits.insertMany([ {name: "apple", origin: "usa", price: 5}, {name: "orange", origin: "italy", price: 3}, {name: "mango", origin: "malaysia", price: 3} ])
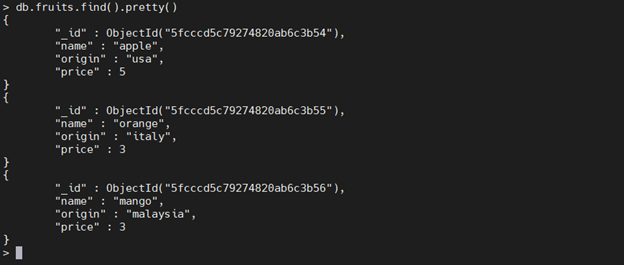
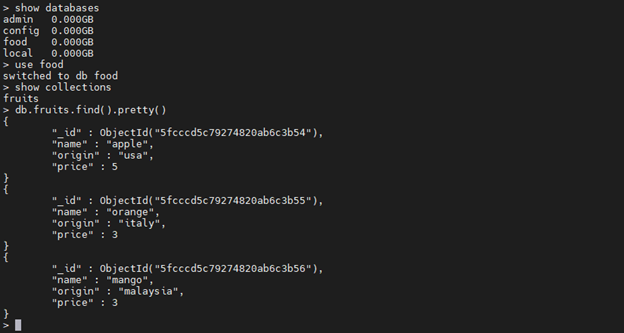
Search for the documents using the find command.
db.fruits.find().pretty()
The MongoDB container will act like any normal MongoDB installation, with no concerns about the underlying software and hardware configuration. Using the exit command, we can exit both the MongoDB shell and container shell.

External connections to MongoDB container
While creating the MongoDB container, we mapped the internal MongoDB port to the corresponding port in the server, exposing the MongoDB container to external networks.
The following MongoDB Docker Compose example demonstrates how we can connect to the container from an external endpoint by simply pointing the mongo command to the appropriate server and port.
mongo 10.10.10.60:27017
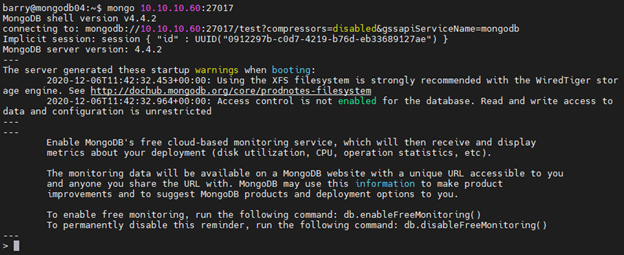
The find command in our MongoDB Docker Compose example will search for the fruits collection and its documents to verify that we are connected to the MongoDB container.
show databases use food show collections db.fruits.find().pretty()
Data resilience and recreating the MongoDB Docker container
We’ve mapped the database to a local folder so that, even if you remove the container, you can use the saved data in the local folder to recreate a new MongoDB container.
Let’s test that. We’ll:
- Remove the container using the docker-compose down.
- Delete the associated images.
- Recreate a new MongoDB database using the Compose file and local database files.
Remove the MongoDB container.
sudo docker-compose down

Remove the local mongo image.
sudo docker rmi mongo
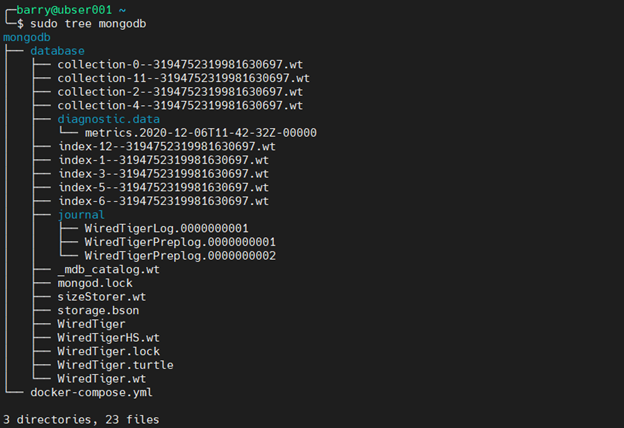
Verify the local database files.
From the output below, we can identify that even though we removed the containers, the data mapped to a local directory did not get removed.
sudo tree mongodb
Recreate a new MongoDB Docker container.
Now, we will recreate the container using the original docker-compose.yml file. We execute the following command in the “mongodb” folder.
sudo docker-compose up -d
Verify the data in the MongoDB container.
Let’s now access the bash shell in the container and check for the “fruits” collections.
sudo docker exec -it mongodb bash

show databases use food db.fruits.find().pretty()
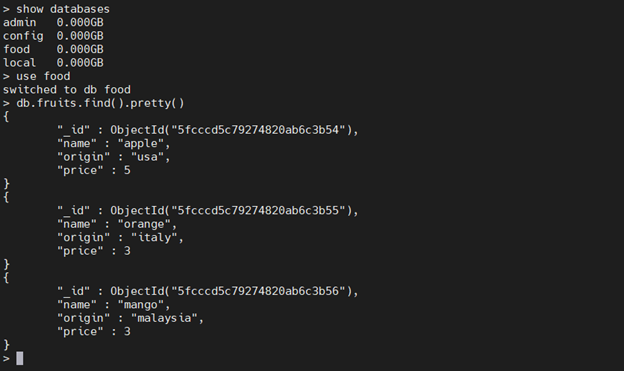
The result indicates we created the new container with the local database information associated with the new container.
Additionally, we can simply move the container by moving the local folder structure to a new server and creating a container using the docker-compose.yml file. You can use Docker volumes instead of locally saving the data to increase the portability of the database.
Monitoring the MongoDB container log files
Every container creates logs that you can use to monitor and debug the container. We can access the container logs using the Docker logs command with the container name to be monitored.
sudo docker logs mongodb
Setting up advanced Docker containers for MongoDB
In this section, we’ll create a secure MongoDB container that requires a username and password to access the database.
In earlier MongoDB Docker Compose examples, we mapped the database data to a local folder. This method is tedious and requires manual intervention when moving the Docker container. Using Docker volumes, we can create Docker-native, persistent volumes that you can easily transfer between Docker installations.
Although we can use the CLI to manipulate the MongoDB instance, a graphical user interface (GUI) is more convenient.
Mongo Express is a web-based MongoDB administration interface that also can be run as a containerized application.
The docker-compose file comes in handy as a single YAML file that captures all the requirements.
docker-compose.yml
version: "3.8"
services:
mongodb:
image: mongo
container_name: mongodb
environment:
- MONGO_INITDB_ROOT_USERNAME=root
- MONGO_INITDB_ROOT_PASSWORD=pass12345
volumes:
- mongodb-data:/data/db
networks:
- mongodb_network
ports:
- 27017:27017
healthcheck:
test: echo 'db.runCommand("ping").ok' | mongo 10.10.10.60:27017/test --quiet
interval: 30s
timeout: 10s
retries: 3
restart: unless-stopped
mongo-express:
image: mongo-express
container_name: mongo-express
environment:
- ME_CONFIG_MONGODB_SERVER=mongodb
- ME_CONFIG_MONGODB_ENABLE_ADMIN=true
- ME_CONFIG_MONGODB_ADMINUSERNAME=root
- ME_CONFIG_MONGODB_ADMINPASSWORD=pass12345
- ME_CONFIG_BASICAUTH_USERNAME=admin
- ME_CONFIG_BASICAUTH_PASSWORD=admin123
volumes:
- mongodb-data
depends_on:
- mongodb
networks:
- mongodb_network
ports:
- 8081:8081
healthcheck:
test: wget --quiet --tries=3 --spider http://admin:[email protected]:8081 || exit 1
interval: 30s
timeout: 10s
retries: 3
restart: unless-stopped
volumes:
mongodb-data:
name: mongodb-data
networks:
mongodb_network:
name: mongodb_network
Now, let’s break down the Compose file given above. First, we have created two services:
- mongodb
- mongo-express
mongodb service
We configured the root username and password of the “mongodb” container using the following environment variables:
- MONGO_INITDB_ROOT_USERNAME
- MONGO_INITDB_ROOT_PASSWORD
We mapped the data volume to mongodb-data Docker volume, and defined the network as mongodb_network, while opening port 27017.
mongo-express service
The environment variables of the mongo-express container are:
- ME_CONFIG_MONGODB_SERVER – MongoDB service (mongodb)
- ME_CONFIG_MONGODB_ENABLE_ADMIN – Enable access to all databases as admin
- ME_CONFIG_MONGODB_ADMINUSERNAME – Admin username of the MongoDB database
- ME_CONFIG_MONGODB_ADMINPASSWORD – Admin password of the MongoDB database
- ME_CONFIG_BASICAUTH_USERNAME – Mongo-Express web interface access username
- ME_CONFIG_BASICAUTH_PASSWORD – Mongo-Express web interface access password
Additionally, we configured the mongo-express service to depend on the mongodb service. We assigned the network the same mongodb_network, and mapped the volumes to mongodb-data volume. We exposed the port 8081 to allow access to the web interface.
We can monitor both services using Docker health checks. The mongodb service will ping the MongoDB database, while the mongo-express service will try to access the web page using the given credentials.
Finally, we defined a volume called “mongodb-data” and a network called “mongodb_network” for the project.
Start the Docker Compose file.
sudo docker-compose up -d
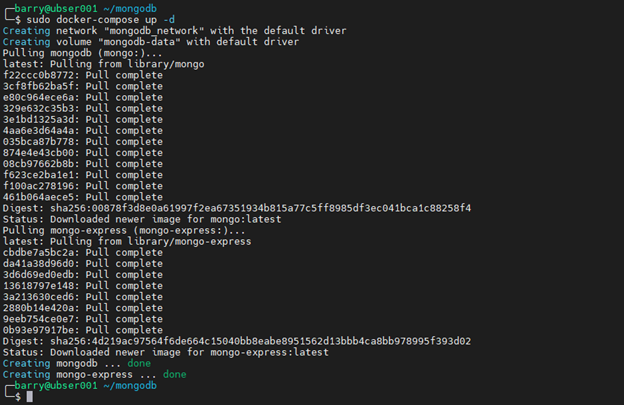
The above output contains no errors, so we can assume that all the services are created successfully. Because we have added health checks for both services, we can verify it by using the Docker ps command.
sudo docker ps -a

The Docker ps command prints the health status of the container. This health status is only available if you have defined a health check for the container.
Monitoring with Mongo Express
Now, let’s go to the Mongo Express web interface using the server IP (http://10.10.10.60:8081.)
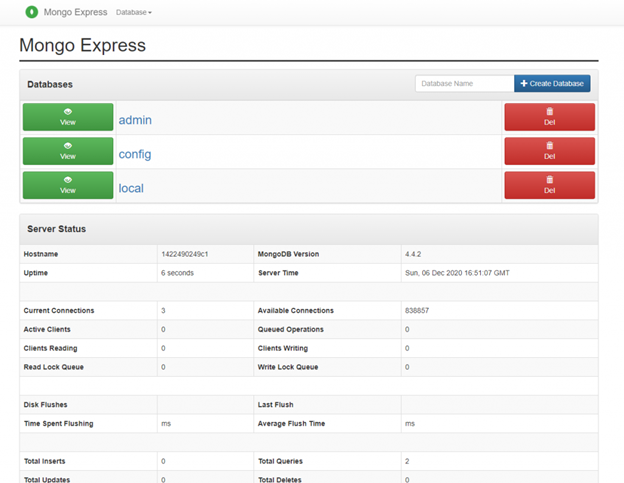
The Mongo Express interface provides a convenient way to interact with the MongoDB database. The Mongo Express interface also provides an overview status of the MongoDB server instance, providing a simple monitoring functionality.
Conclusion
We created this Docker MongoDB tutorial because of the popularity of MongoDB among NoSQL databases and the benefits you can achieve by using it in a Docker container.
Using MongoDB in Docker containers creates consistent development and production environments for smoother deployments. Unlike virtual machines, Docker containers demand fewer resources.
With a mastery of simple and advanced Docker containers, your software development processes can be far more efficient and trouble-free.
]]>Every data engineer must develop an understanding of the bias and variance tradeoff in machine learning (ML).
ML is used in more applications every day. Speech and image recognition, fraud detection, chatbots, and generative AI, are now commonplace uses of this technology. The growing use of ML is bringing the intricacies of how machine learning algorithms work out of specialized labs and into the mainstream of information technology.
Machine learning models cannot be a black box. Data engineers and users of large data sets must understand how to create and evaluate various algorithms and learning requirements when building and evaluating their ML models. Bias and variance in machine learning affect the overall accuracy of any model, trust in its outputs and outcomes, and its capacity to train machines to learn.
In this article, we will discuss what bias and variance in machine learning are. We will also touch on how to deal with the bias and variance tradeoff in developing useful algorithms for your ML applications.
(New to ML? Read our ML vs AI explainer.)
Bias vs. variance, and the tradeoff
Bias and variance are two sources of error in predictive models. Getting the right balance between the bias and variance tradeoff is fundamental to effective machine learning algorithms. Here is a quick explanation of these concepts:
- Bias. Bias refers to error caused by a model for solving complex problems that is over simplified, makes significant assumptions, and misses important relationships in your data.
- Variance. Variance is an error caused by an algorithm that is too sensitive to fluctuations in data, creating an overly complex model that sees patterns in data that are actually just randomness.
- Bias–variance tradeoff. Minimizing errors caused by oversimplification and excessive complication requires finding the right balance or tradeoff between the two.
What is bias in machine learning?

Bias in ML is sometimes called the “too simple” problem. Bias is considered a systematic error that occurs in the machine learning model itself due to incorrect assumptions in the ML process.
Technically, we can define bias as the error between average model prediction and the ground truth. Moreover, it describes how well the model matches the training data set:
- High bias. A model with a higher bias would not match the data set closely.
- Low bias. A low bias model will closely match the training data set.
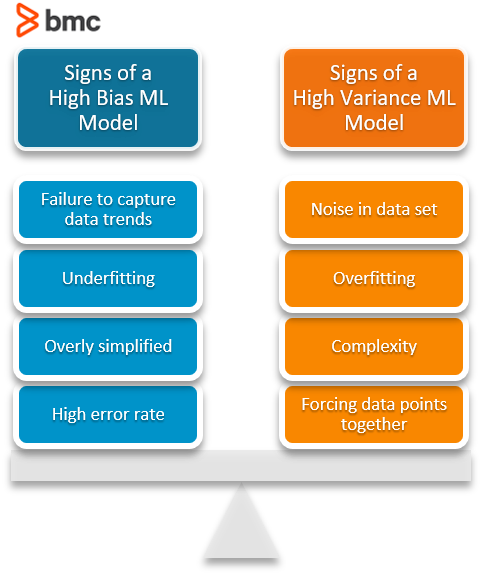
Characteristics of a high bias model include:
- Failure to capture proper data trends
- Potential towards underfitting
- More generalized/overly simplified
- High error rate
What is variance in machine learning?

Variance in machine learning is sometimes called the “too sensitive” problem. Variance in ML refers to the changes in the model when using different portions of the training data set.
Simply stated, variance is the variability in the model prediction—how much the ML function can adjust depending on the given data set. Variance comes from highly complex models with a large number of features.
- Low variance. Models with high bias will have low variance.
- High variance. Models with high variance will have a low bias.
All these contribute to the flexibility of the model. For instance, a model that does not match a data set with a high bias will create an inflexible model with a low variance that results in a suboptimal machine learning model.
Characteristics of a high variance model include:
- Noise in the data set
- Potential towards overfitting
- Complex models
- Trying to put all data points as close as possible
Getting started with AIOps is easy. Learn how you can manage escalating IT complexity with ease! ›
Underfitting and overfitting
You can see from our fruit example how important it is that your model matches the data. How well your model “fits” the data directly correlates to how accurately it will perform in making identifications or predictions from a data set.
- Underfitting happens when your model is too simple to capture variations and patterns in your data. The machine doesn’t learn the right characteristics and relationships from the training data, and thus performs poorly with subsequent data sets. It might be trained on a red apple and mistake a red cherry for an apple.
- Overfitting happens when a model is too complex, with too much detail and random fluctuations or noise in the training data set. The machine erroneously sees this noise as true patterns, and thus is not able to generalize and see real patterns in subsequent data sets. It might be trained on many details of a specific type of apple and thus cannot find apples if they don’t have all these specific details.
Bias–variance trade-off
Bias and variance are inversely connected. It is impossible to have an ML model with a low bias and a low variance.
When a data engineer modifies the ML algorithm to better fit a given data set, it will lead to low bias—but it will increase variance. This way, the model will fit with the data set while increasing the chances of inaccurate predictions.
The same applies when creating a low variance model with a higher bias. While it will reduce the risk of inaccurate predictions, the model will not properly match the data set.
It’s a delicate balance between these bias and variance. Importantly, however, having a higher variance does not indicate a bad ML algorithm. Machine learning algorithms should be able to handle some variance.
We can tackle the trade-off in multiple ways…
- Increasing the complexity of the model to count for bias and variance, thus decreasing the overall bias while increasing the variance to an acceptable level. This aligns the model with the training dataset without incurring significant variance errors.
- Increasing the training data set can also help to balance this trade-off, to some extent. This is the preferred method when dealing with overfitting models. Furthermore, this allows users to increase the complexity without variance errors that pollute the model as with a large data set.
A large data set offers more data points for the algorithm to generalize data easily. However, the major issue with increasing the trading data set is that underfitting or low bias models are not that sensitive to the training data set. Therefore, increasing data is the preferred solution when it comes to dealing with high variance and high bias models.
This table lists common algorithms and their expected behavior regarding bias and variance:
| Algorithm | Bias | Variance |
| Linear Regression | High Bias | Less Variance |
| Decision Tree | Low Bias | High Variance |
| Bagging | Low Bias | High Variance (Less than Decision Tree) |
| Random Forest | Low Bias | High Variance (Less than Decision Tree and Bagging) |
Ready to discover how BMC Helix for ServiceOps can transform your business?
Bias and variance calculation Python example
Let’s put these concepts into practice—we’ll calculate bias and variance using Python.
The simplest way to do this would be to use a library called mlxtend (machine learning extension), which is targeted for data science tasks. This library offers a function called bias_variance_decomp that we can use to calculate bias and variance.
We will be using the Iris data data set included in mlxtend as the base data set and carry out the bias_variance_decomp using two algorithms: Decision Tree and Bagging.
Decision tree example
from mlxtend.evaluate import bias_variance_decomp
from sklearn.tree import DecisionTreeClassifier
from mlxtend.data import iris_data
from sklearn.model_selection import train_test_split
# Get Data Set
X, y = iris_data()
X_train_ds, X_test_ds, y_train_ds, y_test_ds = train_test_split(X, y,
test_size=0.3,
random_state=123,
shuffle=True,
stratify=y)
# Define Algorithm
tree = DecisionTreeClassifier(random_state=123)
# Get Bias and Variance - bias_variance_decomp function
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
tree, X_train_ds, y_train_ds, X_test_ds, y_test_ds,
loss='0-1_loss',
random_seed=123,
num_rounds=1000)
# Display Bias and Variance
print(f'Average Expected Loss: {round(avg_expected_loss, 4)}n')
print(f'Average Bias: {round(avg_bias, 4)}')
print(f'Average Variance: {round(avg_var, 4)}')
Result:

Bagging example
from mlxtend.evaluate import bias_variance_decomp
from sklearn.tree import DecisionTreeClassifier
from mlxtend.data import iris_data
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
# Get Data Set
X, y = iris_data()
X_train_ds, X_test_ds, y_train_ds, y_test_ds = train_test_split(X, y,
test_size=0.3,
random_state=123,
shuffle=True,
stratify=y)
# Define Algorithm
tree = DecisionTreeClassifier(random_state=123)
bag = BaggingClassifier(base_estimator=tree,
n_estimators=100,
random_state=123)
# Get Bias and Variance - bias_variance_decomp function
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
bag, X_train_ds, y_train_ds, X_test_ds, y_test_ds,
loss='0-1_loss',
random_seed=123,
num_rounds=1000)
# Display Bias and Variance
print(f'Average Expected Loss: {round(avg_expected_loss, 4)}n')
print(f'Average Bias: {round(avg_bias, 4)}')
print(f'Average Variance: {round(avg_var, 4)}')
Result:
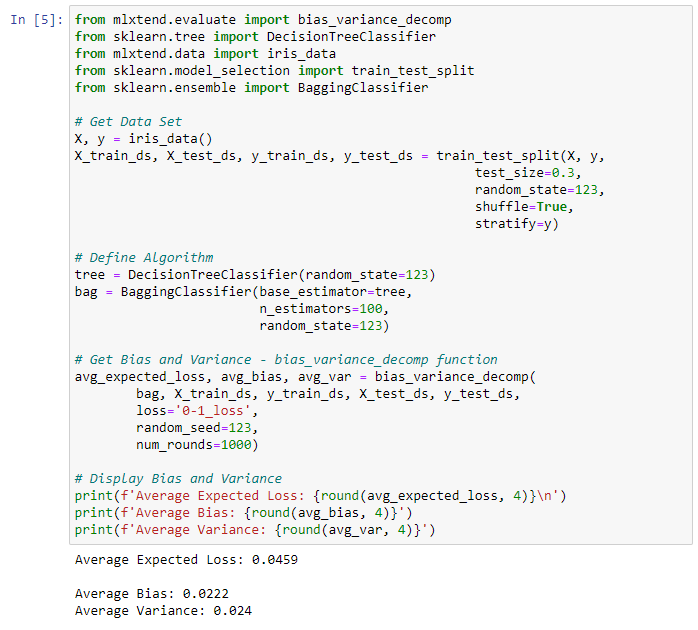
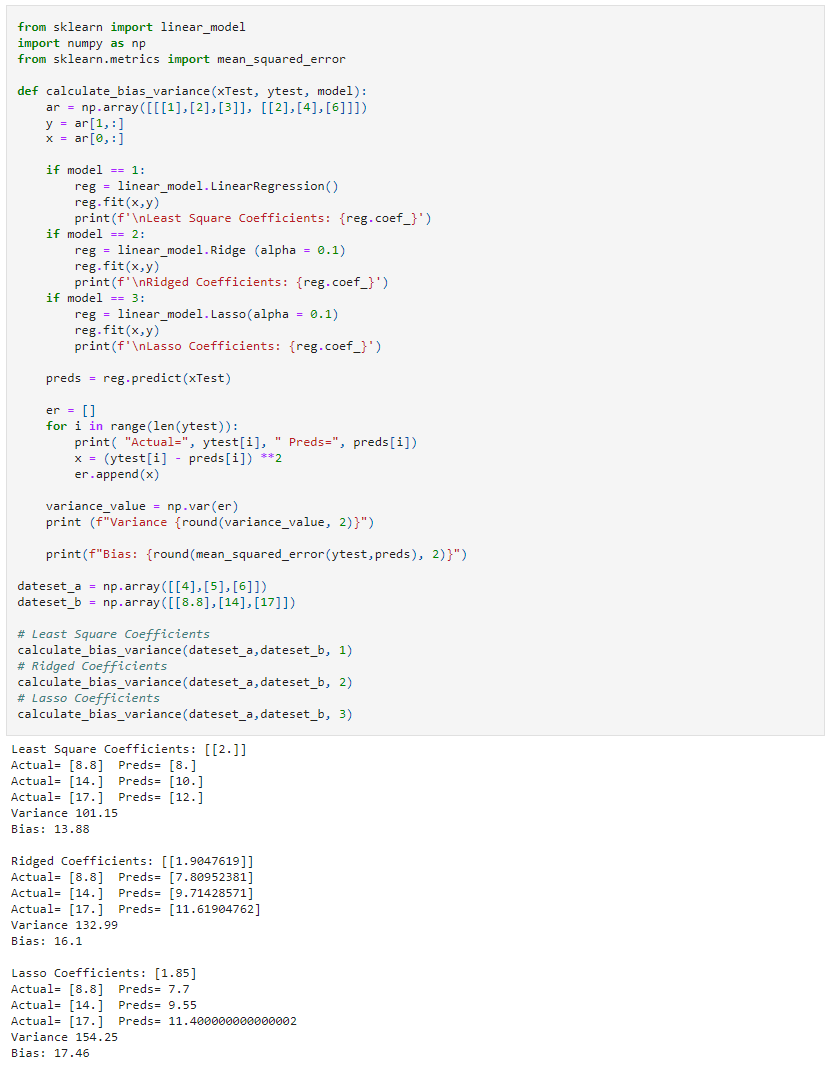
Each of the above functions will run 1,000 rounds (num_rounds=1000) before calculating the average bias and variance values. We can reduce the variance without affecting bias, using a bagging classifier. The higher the algorithm complexity, the lower the variance.
In the following example, we will look at three different linear regression models: least-squares, ridge, and lasso, using sklearn library. Since they are all linear regression algorithms, their main difference will be the coefficient value.
We can see those different algorithms lead to different outcomes in the ML process (bias and variance).
from sklearn import linear_model
import numpy as np
from sklearn.metrics import mean_squared_error
def calculate_bias_variance(xTest, ytest, model):
ar = np.array([[[1],[2],[3]], [[2],[4],[6]]])
y = ar[1,:]
x = ar[0,:]
if model == 1:
reg = linear_model.LinearRegression()
reg.fit(x,y)
print(f'nLeast Square Coefficients: {reg.coef_}')
if model == 2:
reg = linear_model.Ridge (alpha = 0.1)
reg.fit(x,y)
print(f'nRidged Coefficients: {reg.coef_}')
if model == 3:
reg = linear_model.Lasso(alpha = 0.1)
reg.fit(x,y)
print(f'nLasso Coefficients: {reg.coef_}')
preds = reg.predict(xTest)
er = []
for i in range(len(ytest)):
print( "Actual=", ytest[i], " Preds=", preds[i])
x = (ytest[i] - preds[i]) **2
er.append(x)
variance_value = np.var(er)
print (f"Variance {round(variance_value, 2)}")
print(f"Bias: {round(mean_squared_error(ytest,preds), 2)}")
dateset_a = np.array([[4],[5],[6]])
dateset_b = np.array([[8.8],[14],[17]])
# Least Square Coefficients
calculate_bias_variance(dateset_a,dateset_b, 1)
# Ridged Coefficients
calculate_bias_variance(dateset_a,dateset_b, 2)
# Lasso Coefficients
calculate_bias_variance(dateset_a,dateset_b, 3)
Result:
Scale operational effectiveness with an artificial intelligence for IT operations. Learn more about AIOps with BMC! ›
Considering bias and variance is crucial
Bias and variance are two key components that you must consider when developing any good, accurate machine learning model.
- Bias creates consistent errors in the ML model, which represents a simpler ML model that is not suitable for a specific requirement.
- On the other hand, variance creates variance errors that lead to incorrect predictions seeing trends or data points that do not exist.
Users need to consider both these factors when creating an ML model. Generally, your goal is to keep bias as low as possible while introducing acceptable levels of variances. This can be done either by increasing the complexity or increasing the training data set.
In this balanced way, you can create an acceptable machine learning model.
Related reading
]]>The database administrator (DBA) plays a key role in many companies. Today’s most valuable companies are the ones that make the best use of data. The database administrator is key to unlocking that value.
The tasks of database administration in the management of data and IT systems is a critical exercise, particularly in a time where data privacy regulation is a hot topic.
Database administrator roles and responsibilities have evolved over time, given the evolution of data types and sources, along with data storage options. Let’s review the current status of this career field and see what the future holds for database administrator roles.
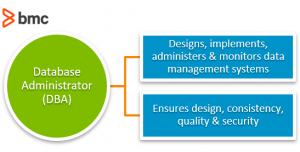
What is a database administrator (DBA)?
A database administrator, or DBA for short, designs, implements, administers, and monitors data management systems and ensures consistency, quality, security, and compliance with rules and regulations.
The role of DBA has evolved into a mission-critical function. A DBA in database management involves the installing, configuring, monitoring, maintaining, and improving the performance of databases and data stores, according to Skills Framework for the Information Age–SFIA 8. A solution architect may design the overall framework or structure of the databases, but the job of implementing and maintaining belongs to DBA roles.
(Read our data architecture explainer.)
Where do database administrators work?
The database administrator role has a place in nearly every organization, to at least some degree. The industries that employ the most people in database administration include tech fields such as computer systems design and information management.
Many also work in information-intensive businesses such as finance, insurance, and educational services. The management of companies and enterprises as a whole also drives the demand for DBAs.
Database administrator responsibilities
Now that we have defined what a database administrator is, we can take a deeper dive into the responsibilities that might be part of a database administrator job description. The day-to-day activities that a DBA performs may include:
- Creating and maintaining database standards and policies.
- Supporting database design, creation, and testing activities.
- Managing the database availability and performance, including incident and problem management.
- Administering database objects to achieve optimum utilization.
- Defining and implementing event triggers that will alert on potential database performance or integrity issues.
- Performing database housekeeping, such as tuning, indexing, etc.
- Monitoring usage, transaction volumes, response times, concurrency levels, etc.
- Implementing security measures and frameworks, while ensuring compliance.
- Identifying, reporting, and managing database security issues, audit trails, and forensics.
- Designing database backup, archiving, and storage strategy.
- Installing upgrades and patches to various apps.
Are you ready to harness the power of data? See how DataOps with BMC can transform your analytics. ›
What is the average wage for DBAs?
Qualified people in this field, depending on the specifics of the various database administrator roles and the DBA tasks they handle, tend to earn on the high side on average. The median salary for a database administrator was $117,450 in May 2023. Those working in companies in the computer systems sector earned almost twice as much as those in educational services.
Database administrator requirements and education

At a bare minimum, database administrator job descriptions seek people who:
- Have a background in computer science, information technology, or engineering.
- Are conversant with structured query language (SQL) and relevant database technologies (whether proprietary or open source.)
- Understand coding and service management to some degree.
Relevant database technologies include SQL Server, MySQL, Oracle, IBM Db2, and MongoDB, among others. You don’t have to be certified in all of them, but a working knowledge of a few of them is required.
The European e-Competence framework (e-CF) outlines five associated competencies that the DBA should have. These competences are all proficiency level 3, on a scale of 1 to 5:
| e-CF Area | e-CF Competence | Level 3 |
|---|---|---|
| Build | Application Development | Acts creatively to develop applications and to select appropriate technical options. Accounts for others’ development activities. Optimizes application development, maintenance, and performance by employing design patterns and by reusing proven solutions. |
| Component integration | Accounts for own and others’ actions in the integration process. Complies with appropriate standards and change control procedures to maintain integrity of the overall system functionality and reliability. | |
| Run | Change Support | Ensures the integrity of the system by controlling the application of functional updates, software, or hardware additions and maintenance activities. Complies with budget requirements. |
| Information and Knowledge Management | Analyzes business processes and associated information requirements and provides the most appropriate information structure. | |
| Manage | Information Security Management | Evaluates security management measures and indicators and decides if compliant to information security policy. Investigates and instigates remedial measures to address any security breaches. |
You will need additional soft skills for success across database administrator roles and responsibilities:
- Business awareness and understanding of business requirements of IT
- Excellent problem-solving and analytical skills
- Good communication, teamwork, and negotiation skills
- Good organizational skills
- Flexibility and adaptability
- Excellent business relationship and user support skills
DBA career development
In mapping your career development plan, the following four areas of responsibility are defined in the Skills Framework for the Information Age (SFIA 8:
Level 2 Database Administrator (Assist)
You will work under the guidance of someone with more experience, but will have some discretion in planning some of your work and resolving some issues. In this role, you will:
- Assist in database support activities.
- Collaborate with team members in addressing user needs.
- Contribute to issue resolution and discussions.
- Identify your own development opportunities and take advantage of chances to learn more.
Level 3 Database Administrator (Apply)
As you progress in experience and seniority, you will begin to work with greater autonomy. You will meet agreed milestones and will make judgments about responding to issues and when to escalate them to a higher level. DBA tasks at this level include:
- Performing standard database maintenance and administration tasks.
- Usings database management system software and tools to collect performance statistics.
- Interacting with customers, suppliers, and partners.
- Collaborating with others on the team, making substantive contributions.
Level 4 Database Administrator (Enable)
With an understanding of the general direction of your team, you have discretion in deciding what issues and assignments to prioritize. You will manage plans and schedules and keep track of how your team is meeting objectives and targets. People in this role:
- Develop and configure tools to enable automation of database administration tasks.
- Monitor performance statistics and create reports.
- Identify and investigate complex problems and issues and recommend corrective actions.
- Perform routine configuration, installation, and reconfiguration of database and related products.
Level 5 Database Administrator (Ensure, Advise)
You will need to be a self-starter and self-manager in this leadership role. You will be making decisions about assigning work, keeping to deadlines, and managing the budget. A database administrator job description for a DBA at this level may specify that they:
- Identify, evaluate, and manage the adoption of database administration tools and processes, including automation.
- Develop and maintain procedures and documentation for databases.
- Contribute to the setting of standards for definition, security, and integrity of database objects and ensure conformance to these standards.
- Manage database configuration including installing and upgrading software and maintaining relevant documentation.
- Monitor database activity and resource usage.
- Optimize database performance and plan for forecast resource needs.
Experience the power of efficient data workflow orchestration with Control-M! ›
Outlook for DBAs
Demand for data continues to explode and evolve. Jobs in this field are expected to grow by 8% between 2022 and 2032.
The idea of information organized in a logical framework is giving way to unstructured data in the form of text, images, sensor information, audio, and videos. Data generated from more sources, such as mobile devices, ecommerce, internet of things (IoT), artificial intelligence (AI), and social media.
The result is that the title of a “database administrator” is morphing into a “data administrator,” who manages structured (database) and unstructured (big data) data sets.
Since most digital organizations are no longer restricted to transactional data only, the modern DBA must be conversant with file, block and object storage solutions.
And because of the sheer volume of data, as well as the growing reliance on AI and machine learning solutions for data processing, most data is now stored in the cloud. You will need expertise in cloud architectures and technologies, including data lakes and big data solutions like Hadoop.
The rise of DevOps methodology as the preferred model for end-to-end product management means that you need a broad base of knowledge across several areas of specialization. You will likely work in an autonomous environment with platform engineers to develop automated self-service tools. Software developers can use the tools you develop to create the data solutions they require for their applications.
A career in database administration will also require you to add software engineering capabilities to your repertoire.
Leverage automation powered by AI and machine learning to provide world-class data management with BMC AMI Data. ›
DBAs must acknowledge data privacy
Protecting data has become the focus of regulation across the world, with global enterprises being subject to a web of complex and intersecting laws and requirements.
Failure to comply with regulations, such as the sweeping GDPR laws that protect user/customer privacy rights, puts the reputation and data of your organization at risk and exposes your enterprise to hefty fines. For this reason, data management is now a critical corporate governance imperative.
To better comply with the cybersecurity challenge, various cybersecurity frameworks such as CISA, NIST, and ISO 27001, and services that automate compliance have emerged. An expanding DBA role includes making sure your organization satisfies their requirements, is set up to prevent cybercrimes, can handle audits, and can handle demands for documentation.
Related reading
- BMC Machine Learning & Big Data Blog
- Top DBA Shell Scripts for Monitoring the Database
- What Is a Database Reliability Engineer (DBRE)?
- DataOps Explained: Understand how DataOps leverages analytics to drive actionable business insights
- Are IBM® z/OS® Db2® DBAs Vanishing?
- Today’s Best IT/Tech Certifications: A Complete Guide
In the digital-first global economy, data is everywhere—and always growing. And how companies handle their data pipeline and yield value from their data can be a gamechanger for their business outcomes. We wanted to see how companies are managing their data, and what their data management maturity level is, so we’ve once again partnered with 451 Research, part of S&P Global Market Intelligence, on a survey of 1,100 IT, data, and business professionals from large, global enterprises across multiple industries in 11 countries. We’re excited to announce that our second annual report, “Putting the “Ops” in DataOps: Success factors for operationalizing data,” is out now and available here.
DataOps and data maturity
The survey and report reveal insights into how organizations and data teams can assess and advance their data management maturity to overcome challenges and improve their use of data for competitive advantage. By determining their place within four discrete maturity levels, organizations can make better technology and business decisions to guide their DataOps initiatives and improve their data quality in service of tangible business outcomes. The four levels, as defined in the report, are:
- Developing maturity—The data management strategy is developing, but practices and architecture may not yet be closely linked to critical business outcomes; commonly associated with smaller organizations and businesses that are just beginning to establish and operationalize their practices.
- Functional maturity—The data management strategy is largely developed, with some high-priority practices and architecture linked to critical business outcomes. This level is focused on growth, and businesses are often focused on expanding their practices.
- Proficient maturity—The strategy is fully established, with nearly all practices and architecture linked to critical business outcomes, but due to increasing awareness and complexity, doubts in the capabilities of the business arise.
- Exceptional maturity—The data management strategy is perpetually optimized, with practices and architecture driving novel sources of value. At this “innovation phase” of maturity, established practices are iteratively improved and used for further competitive differentiation.
In addition to discussing data management maturity, the report includes key findings on how organizations are doing now—and what they’re focused on.
Slow adoption of emerging technologies
While companies strive to capitalize on their data to scale operations and improve business outcomes, only a minority of them are leveraging emerging data types. Instead, most are ingesting, landing, and processing the most common (i.e., often legacy or structured) data types. That means they might be missing out on additional useful data in nontraditional formats that could feed critical initiatives like generative artificial intelligence (Gen AI), FinOps, and sustainability.
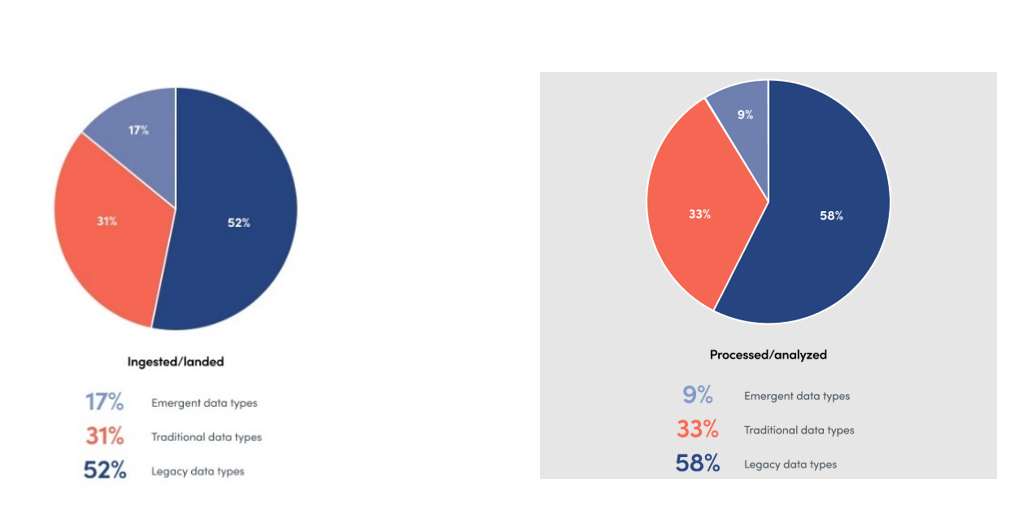
Figure 1. Slow adoption of emerging technologies.
While the overall adoption rate of emerging data types is low, larger organizations—particularly those with 5K+ employees—are keen to tap into them for new initiatives.
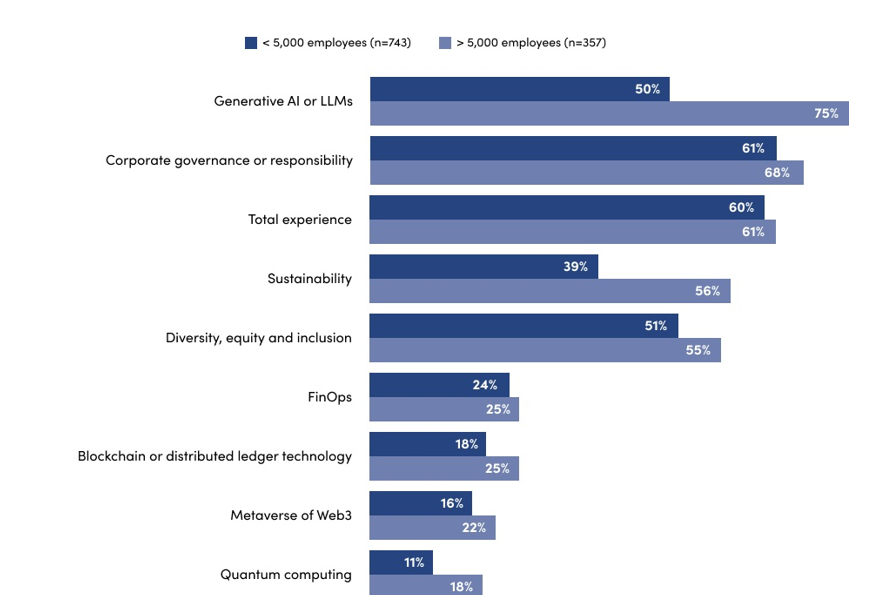
Figure 2. Large organizations are collecting and managing data for use cases in emergent trends.
Top challenges in DataOps and data-driven activities
Data isn’t useful if data orchestration isn’t done well, i.e., that data isn’t getting where it’s most needed, and multi-layered challenges across people, process, and technology can pose a challenge to its distribution.

Figure 3. Top challenges in data-driven activities.
Data maturity and DataOps strategy
One of the strongest correlations in the survey was between an organization’s approach to DataOps methodology and its relative data management maturity level.
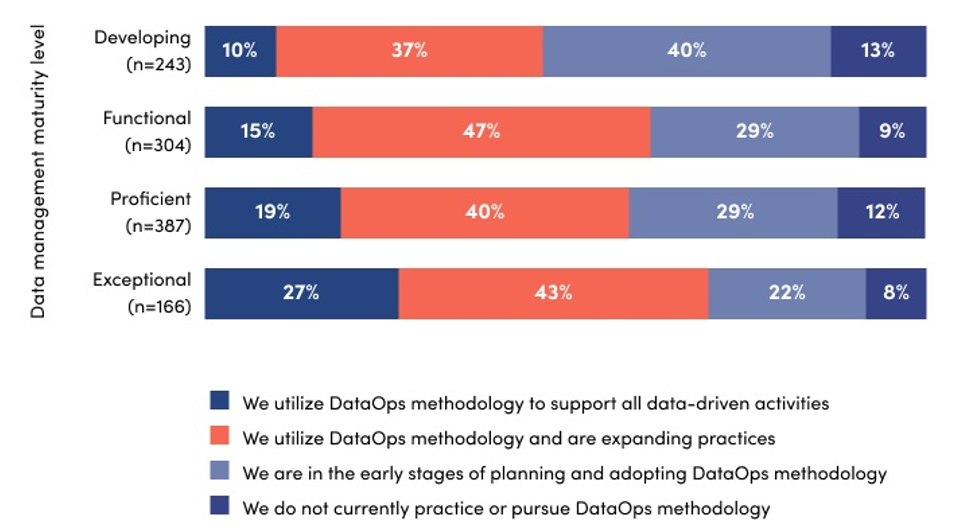
Figure 4. Organizations’ DataOps strategy by data management maturity level.
For more data management and DataOps insights, read the entire report here. To assess your organization’s data maturity level, you can take a free assessment here. This tool was designed to help you determine which areas you need to address to begin advancing your DataOps practice to “exceptional” levels.
]]>In today’s fast-paced digital landscape, the ability to harness the power of artificial intelligence (AI) and machine learning (ML) is crucial for businesses aiming to gain a competitive edge. Amazon SageMaker is a game-changing ML platform that empowers businesses and data scientists to seamlessly navigate the development of complex AI models. One of its standout features is its end-to-end ML pipeline, which streamlines the entire process from data preparation to model deployment. Amazon SageMaker’s integrated Jupyter Notebook platform enables collaborative and interactive model development, while its data labeling service simplifies the often-labor-intensive task of data annotation.
It also boasts an extensive library of pre-built algorithms and deep learning frameworks, making it accessible to both newcomers and experienced ML practitioners. Amazon SageMaker’s managed training and inference capabilities provide the scalability and elasticity needed for real-world AI deployments. Moreover, its automatic model tuning, and robust monitoring tools enhance the efficiency and reliability of AI models, ensuring they remain accurate and up-to-date over time. Overall, Amazon SageMaker offers a comprehensive, scalable, and user-friendly ML environment, making it a top choice for organizations looking to leverage the potential of AI.
Bringing Amazon SageMaker and Control-M together
Amazon SageMaker simplifies the entire ML workflow, making it accessible to a broader range of users, including data scientists and developers. It provides a unified platform for building, training, and deploying ML models. However, to truly harness the power of Amazon SageMaker, businesses often require the ability to orchestrate and automate ML workflows and integrate them seamlessly with other business processes. This is where Control-M from BMC comes into play.
Control-M is a versatile application and data workflow orchestration platform that allows organizations to automate, monitor, and manage their data and AI-related processes efficiently. It can seamlessly integrate with SageMaker to create a bridge between AI modeling and deployment and business operations.
In this blog, we’ll explore the seamless integration between Amazon SageMaker and Control-M and the transformative impact it can have on businesses.
Amazon SageMaker empowers data scientists and developers to create, train, and deploy ML models across various environments—on-premises, in the cloud, or on edge devices. An end-to-end data pipeline will include more than just Amazon SageMaker’s AI and ML functionality, where data gets ingested from multiple sources, transformed, aggregated etc., before training a model and executing AI/ML pipelines with Amazon SageMaker. Control-M is often used for automating and orchestrating end-to-end data pipelines. A good example of end-to-end orchestration is covered in the blog, “Orchestrating a Predictive Maintenance Data Pipeline,” co-authored by Amazon Web Services (AWS) and BMC.
Here, we will specifically focus on integrating Amazon SageMaker with Control-M. When you have Amazon SageMaker jobs embedded in your data pipeline or complex workflow orchestrated by Control-M, you can harness the capabilities of Control-M for Amazon SageMaker to efficiently execute an end-to-end data pipeline that it also includes Amazon SageMaker pipelines.
Key capabilities
Control-M for Amazon SageMaker provides:
- Secure connectivity: Connect to any Amazon SageMaker endpoint securely, eliminating the need to provide authentication details explicitly
- Unified scheduling: Integrate Amazon SageMaker jobs seamlessly with other Control-M jobs within a single scheduling environment, streamlining your workflow management
- Pipeline execution: Execute Amazon SageMaker pipelines effortlessly, ensuring that your ML workflows run smoothly
- Monitoring and SLA management: Keep a close eye on the status, results, and output of Amazon SageMaker jobs within the Control-M Monitoring domain and attach service level agreement (SLA) jobs to your Amazon SageMaker jobs for precise control
- Advanced capabilities: Leverage all Control-M capabilities, including advanced scheduling criteria, complex dependencies, resource pools, lock resources, and variables to orchestrate your ML workflows effectively
- Parallel execution: Run up to 50 Amazon SageMaker jobs simultaneously per agent, allowing for efficient job execution at scale
Control-M for Amazon SageMaker compatibility
Before diving into how to set up Control-M for Amazon SageMaker, it’s essential to ensure that your environment meets the compatibility requirements:
- Control-M/EM: version 9.0.20.200 or higher
- Control-M/Agent: version 9.0.20.200 or higher
- Control-M Application Integrator: version 9.0.20.200 or higher
- Control-M Web: version 9.0.20.200 or higher
- Control-M Automation API: version 9.0.20.250 or higher
Please ensure you have the required installation files for each prerequisite available.
A real-world example:
The Abalone Dataset, sourced from the UCI Machine Learning Repository, has been frequently used in ML examples and tutorials to predict the age of abalones based on various attributes such as size, weight, and gender. The age of abalones is usually determined through a physical examination of their shells, which can be both tedious and intrusive. However, with ML, we can predict the age with considerable accuracy without resorting to physical examinations.
For this exercise, we used the Abalone tutorial provided by AWS. This tutorial efficiently walks users through the stages of data preprocessing, training, and model evaluation using Amazon SageMaker.
After understanding the tutorial’s nuances, we trained the Amazon SageMaker model with the Abalone Dataset, achieving satisfactory accuracy. Further, we created a comprehensive continuous integration and continuous delivery (CI/CD) pipeline that automates model retraining and endpoint updates. This not only streamlined the model deployment process but also ensured that the Amazon SageMaker endpoint for inference was always up-to-date with the latest trained model.
Setting up Control-M for Amazon SageMaker
Now, let’s walk through how to set up Control-M for Amazon SageMaker, which has three main steps:
- Creating a connection profile that Control-M will use to connect to the Amazon SageMaker environment
- Defining an Amazon SageMaker job in Control-M that will define what we want to run and monitor within Amazon SageMaker
- Executing an Amazon SageMaker pipeline with Control-M
Step 1: Create a connection profile
To begin, you need to define a connection profile for Amazon SageMaker, which contains the necessary parameters for authentication and communication with SageMaker. Two authentication methods are commonly used, depending on your setup.
Example 1: Authentication with AWS access key and secret
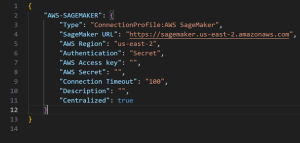
Figure 1. Authentication with AWS access key and secret.
Example 2: Authentication with AWS IAM role from EC2 instance
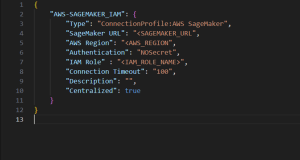
Figure 2. Authentication with AWS IAM role.
Choose the authentication method that aligns with your environment. It is important to specify the Amazon SageMaker job type exactly as shown in the examples above. Please note that Amazon SageMaker is case-sensitive, so make sure to use the correct capitalization.
Step 2: Define an Amazon SageMaker job
Once you’ve set up the connection profile, you can define an Amazon SageMaker job type within Control-M, which type enables you to execute Amazon SageMaker pipelines effectively.
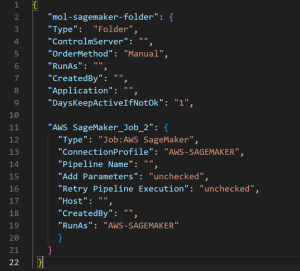
Figure 3. Example AWS SageMaker job definition.
In this example, we’ve defined an Amazon SageMaker job, specifying the connection profile to be used (“AWS-SAGEMAKER”). You can configure additional parameters such as the pipeline name, idempotency token, parameters to pass to the job, retry settings, and more. For a detailed understanding and code snippets, please refer to the BMC official documentation for Amazon SageMaker.
Step 3: Executing the Amazon SageMaker pipeline with Control-M
It’s essential to note that the pipeline name and endpoint are mandatory JSON objects within the pipeline configuration. By executing the “ctm run” command on the pipeline.json file, it activates the pipeline’s execution within AWS.
First, we run “ctm build sagemakerjob.json” to validate our JSON configuration and then the “ctm run sagemakerjob.json” command to execute the pipeline.
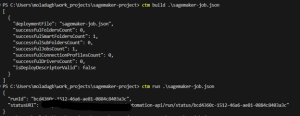
Figure 4. Launching Amazon SageMaker job.
As seen in the screenshot above the “ctm run” command has launched the Amazon SageMaker job. The next screenshot shows the pipeline running from the Amazon SageMaker console.
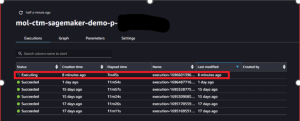
Figure 5. View of data pipeline running in Amazon SageMaker console.
In the Control-M monitoring domain, users have the ability to view job outputs. This allows for easy tracking of pipeline statuses and provides insights for troubleshooting any job failures.
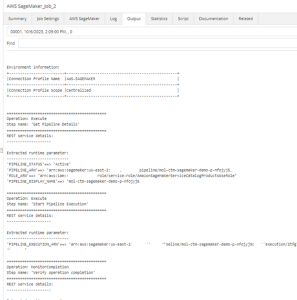
Figure 6. View of Amazon SageMaker job output from Control-M Monitoring domain.
Summary
In this blog, we demonstrated how to integrate Control-M with Amazon SageMaker to unlock the full potential of AWS ML services, orchestrating them effortlessly into your existing application and data workflows. This fusion not only eases the management of ML jobs but also optimizes your overall automation processes.
Stay tuned for more blogs on Control-M and BMC Helix Control-M integrations! To learn more about Control-M integrations, visit our website.
]]>At Marisa, we are proud of our heritage of being a leading Brazilian retailer for 75 years. Much has changed since our founding, and one of the biggest recent changes happened within our IT systems. Our team was hired by the CIO to lead a major transformation project to break down silos and integrate data from all aspects of the business so we could better connect with our customers.
To get the new business insights we required, we knew we would need new tools. SAP® would remain our system of record, but beyond that we were not committed to keeping many elements of our current-generation system, which included Control-M. Our team had the freedom to completely modernize and select the software and other tools that would best fit our goals and future-proof our business. We used that flexibility create an infrastructure designed to take advantage of the powerful data, analytics, and reporting capabilities available today.
The result is a hybrid cloud environment with data being used simultaneously for analytics and other functions in multiple locations. Some of the key elements include:
- SAP Business Warehouse (SAP BW)
- Informatica
- Data Lake on Amazon Web Services (AWS)
- Azure Databricks
- SQL Server
- Amazon Redshift
- Power BI
- MicroStrategy
- Airflow
- Control-M
Yes, Control-M is on the list, despite our initial thought that we would have to replace it because so many workloads and systems were being updated or replaced.
After we identified many of the elements that would be essential in our responsive new architecture, we began to focus on how we could integrate and orchestrate it all. The complexity became frustrating as we learned about the limitations that each component had for integrating its workflows with others. We had counted on Airflow to solve those challenges, but it had its own limitations. That was the point where we realized Control-M was not part of the problem with our IT systems, it was an essential part of the solution.
Our modernization was driven by the principle of bringing together data from more sources, using best-of-breed solutions. We saw that the limitations of domain-specific tools would be a barrier to realizing our vision and getting the most complete insights possible. We then took a closer look and realized that Control-M was capable of doing much more than what we had been using for. That includes its many integrations with modern data and cloud technologies, so our staff could continue to work with their preferred tools, while allowing Control-M to orchestrate all the operations.
The daily executive report we produce is an excellent example of how everything comes together. Known in the corporate offices as “The Newspaper,” the report consists of a series of dashboards with data and visualizations that show all the leading business indicators and developments from the previous day. It shows daily sales by department and channel (physical stores, e-commerce) plus average receipts, margins, inventory levels, Net Promoter Score (NPS), supply chain updates, and much more. Like a real newspaper, the report relies on information from hundreds of sources and must be produced within strict service level agreements (SLAs). After stores close, we have seven hours to gather, process, and assimilate this data and deliver it to executives before their workday begins the next morning.
Various structured and unstructured data from point of sale (POS), customer relationship management (CRM), inventory, shipping, HR, and other systems is loaded into our SAP Business Warehouse. We use the data lake to produce 18 different reports that are customizable to different business operations and individuals. The process involves our enterprise resource planning (ERP) and all the other systems previously referenced.
Control-M plays the crucial role of being the overall orchestrator. Just for the file transfers to the data lake, Control-M executes 92 complex workflows that require integrations with 12 separate systems. Control-M’s out-of-the-box integrations with Amazon S3, Azure Databricks, Informatica Cloud, and SAP have been integral, as has its connection profiles that allow us to easily build integrations to other environments. We take advantage of the integration with Airflow to orchestrate our data pipelines, enabling our development and operations teams to use the tools they know best, with Control-M handling the orchestration. Control-M is highly scalable and ensures Airflow jobs run reliably in production.
Control-M doesn’t only connect all the pieces in our new environment, it continually monitors the workflows running across them to ensure we have no interruptions. We recently created a centralized enterprise monitoring center with integration between Control-M and our ITSM system at the core. As part of that process, we used Control-M to consolidate activities, thereby eliminating more than 200 recurring jobs. Control-M SLA Management proactively identifies potential workflow execution delays and initiates fixes or notifications. We built a feature that automatically issues a notification via WhatsApp to the appropriate business and operations staff if there is a potential issue with their critical jobs. Our environment is much more complex than it used to be, but we are more responsive and data-driven than ever.
These are some of the successes we’ve achieved in the first year of our transformation program. There’s much more we can do, and now we know Control-M will continue to support us as our systems modernize and our business evolves.
For more information on Control-M, visit bmc.com/controlm.
]]>Scan any business or tech headline right now, and you’re likely to see artificial intelligence (AI) and machine learning (ML), and more specifically the rising niches of GPT and LLMs (generative pre-trained transformer and large language models). GPT and LLMs distill data and return content in natural language, whether as longform narrative, auto-populated answers to questions, or even imagery or videos, all at super-fast speeds. While there’s still much to sort through on what these technologies mean for business, tech, politics, ethics, and more, one thing is clear—they’re breaking new ground for data.
AI, GPT, and LLMs live and die by data. They analyze it, learn from it, and create it, both leveraging and adding to its already explosive growth. And right now, businesses are generating, accumulating, and retaining mountains of it—and spending a considerable amount of money to do so. But to what end?
According to IDC, “Despite spending $290 billion globally on technology and services to increase decision velocity, 42 percent of enterprises report that data is underutilized in their organizations,” and a recent IDC Global Data Sphere predicts that by 2026, seven petabytes of data will be created every second. Boston Consulting Group says the comprehensive costs around data are equally staggering, as “spending on data-related software, services, and hardware—which already amounts to about half a trillion dollars globally—is expected to double in the next five years.”
It’s time to put all that juicy data you’ve collected to work, and investing in AI technologies can help you get there. While GPT and LLM solutions are gaining a reputation for what they can create, they’re also being put into practice for DataOps practices and analytics solutions that can help you make sense of all that data in the first place. Today’s data is so complex that organizations cannot unravel it without the power of AI.
As I covered in my previous blog, DataOps is all about getting your arms around your data by improving data quality, gaining better business insights, and expanding innovation and cloud efficiency. AI and AI-derived technologies can help on all three fronts.
AI can be used to collate, contextualize, and analyze your hard-won proprietary data and then help you use it to learn about your business and your customers. With AI combing through data, you can uncover new insights that were previously inconceivable even a few years ago—and make informed decisions about which data is no longer needed, still missing, needs more details, and so on. From there, that data can be used to train GPT and LLM tools that advance and expand your business and become the targeted solutions and services your customers crave.
The Eckerson Group recently polled data practitioners on LinkedIn and discovered that 43 percent already use LLMs to assist data engineering. In a second poll, 54 percent said they use ChatGPT to help write documentation, 18 percent use it for designing and building pipelines, and another 18 percent are using it to learn new techniques.
Sitting on a mountain of data gets you nowhere if you don’t know what’s in it. With data accumulations surpassing our capacity to sort through, understand, quantify, and qualify it, investing in AI/ML technologies is the way forward. These technologies can help you dig into all that data and yield valuable insights to better understand your business, discover where to expand or change course, identify new opportunities, and ultimately deliver the solutions your customers and stakeholders want.
Making the most of GPT and LLMs relies on a solid data management foundation enabled by the people, process, and technology shifts of a DataOps strategy and methodology. Learn more about how organizations are yielding value from data in Profitable Outcomes Linked to Data-Driven Maturity, a BMC-commissioned study by 451 Research, part of S&P Global Market Intelligence.
]]>Businesses have been on a data collection kick for a while now, and it’s no surprise since IDC says we’ll generate around 221 zettabytes of data by 2026. But if your goal is to turn all that data into insights, where do you start? Do you know what you have? Is it the right data? And, most importantly, is it yielding value for your business?
We commissioned 451 Research, part of S&P Global Market Intelligence, to survey 1,100 IT and data professionals from diverse global regions about what they want from their data, and the challenges they’re facing in achieving those goals. The findings are out now in Profitable Outcomes Linked to Data-Driven Maturity.
The survey revealed a handful of common issues that are impeding progress as businesses try to gather and present a unified view of their data. Among them:
- Meeting the streaming or real-time requirements needed to support data collection from 24×7 business models and Internet of Things devices
- Lack of automation, and a reliance on manual processes and legacy solutions
- Data quality issues with collecting inaccurate and out-of-date information
- Data silos and lack of system interoperability
Additionally, respondents said they need help determining the usability, trustworthiness, and quality of the information they’ve been gathering—and continue to gather—to maximize and optimize that data. If the data is incomplete or incorrect, an organization loses not only the time and effort required to gather and store it in the first place—it also puts itself at risk of noncompliance issues and strategic missteps that damage the bottom line.
Ensuring that you’re gathering the right data, and putting it to good use, requires a tool that can deliver a unified view. Automated capabilities are key to saving time and toil related to data processing, reducing errors, and delivering real-time visibility anytime from anywhere. BMC’s application workflow orchestration solutions, Control-M and BMC Helix Control-M, can help organizations optimize the data they’ve worked so hard to collect, and yield the most value from it.
Control-M simplifies application and data workflow orchestration on-premises or as a service. It makes it easy to build, define, schedule, manage, and monitor production workflows, ensuring visibility and reliability and improving service level agreements (SLAs). BMC Helix Control-M is a software-as-a-service (SaaS)-based solution that integrates, automates, and orchestrates complex data and application workflows across highly heterogeneous technology environments.
Both solutions support the implementation of DataOps, which applies agile engineering and DevOps best practices to the field of data management to better organize, analyze, and leverage data and unlock business value. With DataOps, DevOps teams, data engineers, data scientists, and analytics teams collaborate to collect and implement data-driven business insights.
Automating and orchestrating data pipelines with tools like Control-M and BMC Helix Control-M is integral to DataOps, and can help you yield value from your data and drive better business outcomes by:
- Improving data quality: Once guardrails are in place to identify, collate, and analyze data, you’ll get a better sense of the data you have—and what you still need.
- Gaining better business insights: Now that you’re collecting and analyzing the data you want—and not cluttering it with the data you don’t—it’s an easier task to leverage that information for targeted, revenue-generating activities.
- Expanding innovation and cloud efficiency: With the cost savings achieved through data orchestration and better data processes, you can redirect spend toward innovation initiatives (informed by those very same data insights) that help grow the business.
You can read the full report, Profitable Outcomes Linked to Data-Driven Maturity, here. Visit bmc.com/controlm to learn more about Control-M and bmc.com/helixcontrolm to learn about BMC Helix Control-M.
]]>In 2022, 5.7 million people attended Formula One races around the world, with revenue growing to $2.573 billion. Those two nuggets of intel about one of the biggest sports in the world are data points, and in our latest BMC Transformational Speaker Series, BMC VP of Sales Jeff Hardy and Oracle Senior Director of ISV Success Directors Dan Grant welcomed Formula One Racing Data Analyst Mark Gallagher for a wide-ranging discussion on how data, analytics, and insights are being used to improve efficiency, safety, and more for the organization’s drivers and vehicles. Here are a few excerpts from the conversation.
Mark shared that the organization’s technology evolution since 1950 has been iterative. “We started off by learning how to make cars go faster. We then embraced aerodynamics and learned how to make aircraft go faster, which is effectively what a Formula One car is today. It’s an inverted jet fighter,” he says. “And really the third suite of tools have been digital. And it’s extraordinary to really reflect on the fact that Formula One’s digital transformation has been taking place for more than half of its history.”
“Now to this day, all teams and particularly the more competitive teams [are] utilizing data and analytics. Formula One’s all about action. And we want insights. We want to go on a journey of knowledge rather than a journey of hope. We don’t want to hope we win. We want to know we’re going to win. And that’s where the actionable insights come from.”
While initial analytics revealed what was going right, Mark says he and his team wanted more, and better, data and insights. “We suddenly started wanting a deeper dive. What’s going to help us go faster? What’s going to help us manage risks better? What’s going to enable us to prevent negative outcomes and drive positive outcomes,” he explains. “And that there is the analytics space. Race car drivers haven’t changed very much over the years, but the ecosystem within which they’re operating is night and day difference, thanks to our data-driven environment.”
Mark acknowledged Formula One has had its share of negative outcomes over its history, with fatal accidents occurring on the track every year or multiple accidents per year several years ago, and says the advances they have made through technology mean that younger drivers have never experienced that. “One of the really big changes over the last quarter of a century has been the improvement in our risk management, our ability to use real-time data to spot trends, to analyze failure modes developing, to look at diagnostics in real time and say, ‘Actually, there’s a problem developing,’” he points out.
“When you look at a lot of accidents, they’re caused by a failure, component failure that’s caused by a particular issue arising. In many cases … back in the day, we couldn’t do anything about [that]. But now we can. We can instantaneously, if necessary, call a halt to operations. That doesn’t happen very often, but if we need to, we can call the whole operation.”
“We can manage the lifecycle of up to 80,000 components that we’re going through on the car through the year. And that means that every single aspect and in total, granular detail is being managed so effectively to ensure that we get optimized performance and that risks are minimized. So, when people ask what’s been the big change for me, there is an enormous change.”
Mark adds that airlines have done the same thing. “We’re not the first industry to do that. Every time we get in an aircraft, we’re getting on board something that is inherently safe because of the culture of examining data, forensically examining data from past events in order to ensure that future outcomes are possible,” he explains. “So again, Formula One has looked at aviation and aerospace and said, ‘That’s the level of engineering we’re going to move to.’ And data-driven tools have been integral to that evolution.”
Mark says that between 1950 and 2000, about 45 percent of the time, Formula One cars simply failed due to mechanical issues, and that’s also now become a thing of the past. “Considering that we pride ourselves as engineering companies, we actually weren’t very good at building robust, reliable technology. Today, Formula One world champions can realistically expect to go through a whole season without suffering a single mechanical or technical failure,” he shares.
“I think Lewis Hamilton … went four and a half years without a single significant technical failure. I’ve never had a road car that’s lasted four and a half years with robust technology. So, in Formula One, that quality, that reliability, the foundation stones of the quality of our engineering and outcomes, that has been made possible by our data-driven environment. We’re no longer hoping everything’s going to be okay. We know what the outcome can be.”
If you’re a fan of movies about race cars, you’re familiar with the big moments where a trainer or a coach clicks the stopwatch to marvel at how fast the car got around the track. Mark says they’re light years beyond that. “When we look at the metrics that we are interested in, it all started with the humble stopwatch, [and us wondering], ‘How can we get from A to B faster than our competitors?’” he says.
“How do we get from where we are now to where we want to be more efficiently than our competition? [Now], we are looking at thousands of parameters. We’re talking about 300 sensors on the car, maybe … 1,200 channels of data. The cars are generating … about ten gigabytes of data per lap and a couple of terabytes of data over the weekend from the car. And in terms of the KPIs …we’ve got a ton of people looking at all the metrics. We know the pressures of the tires, we know the temperatures of the tires, we know everything that the human being driving the car is doing.”
“Most of what you’re looking at is all doing fine, but we are really interested in the opportunities, and this is where the actionable insight’s kick in, because [when] you get an anomaly … it’s amazing what we can do. And in its most extreme form, let’s say you were leading the race and you had three laps of the race remaining, and an issue develops on a particular system, we can monitor that system. We can talk to the driver and say, ‘Can you modify your driving because this system is beginning to fail,’ or ‘There’s an issue with this system.’ We might even tell the driver to switch off a particular system. We’ve even had occasions where we’ve had Formula One drivers do the equivalent of control, alt, delete on their steering wheel and literally reset everything and it’s cured a problem.”
“In terms of the metrics that we’re interested in, it’s anything that’s going to show us our benchmark performance against the competition and where the opportunities and the anomalies … and the risks are that we can really dig into some detail that’s going to help us to improve performance.”
“This is why when you see Formula One race car drivers being interviewed after a qualifying session or after a race, they very often say, ‘We’ve got to look at the data.’ And what they’re actually saying is, ‘We’ve got to look at where that issue lies [or] where that opportunity lies.’ It’ll always be the thing or the items which are going to lead to us getting a performance improvement. So, our data-driven environment from the driver’s perspective, is all about managing and gaining insights into any metrics that are going to supercharge our continuous improvement as a race team.”
BMC is keenly interested in the world of data and analytics, and helping companies pursue and improve their data strategies. We recently commissioned 451 Research, part of S&P Global Market Intelligence, to survey 1,100 IT and data professionals from diverse global regions, and those finding have just been released in a new report, Profitable Outcomes Linked to Data-Driven Maturity. You can also check out our deep dive into the world of DataOps here.
To learn more about how the need for speed and the need for data is driving the future of Formula One, Mark’s thoughts on artificial intelligence and autonomous vehicles, and how one driver was so thirsty for data he was checking the screens around the track while driving 200 MPH during a race.
]]>